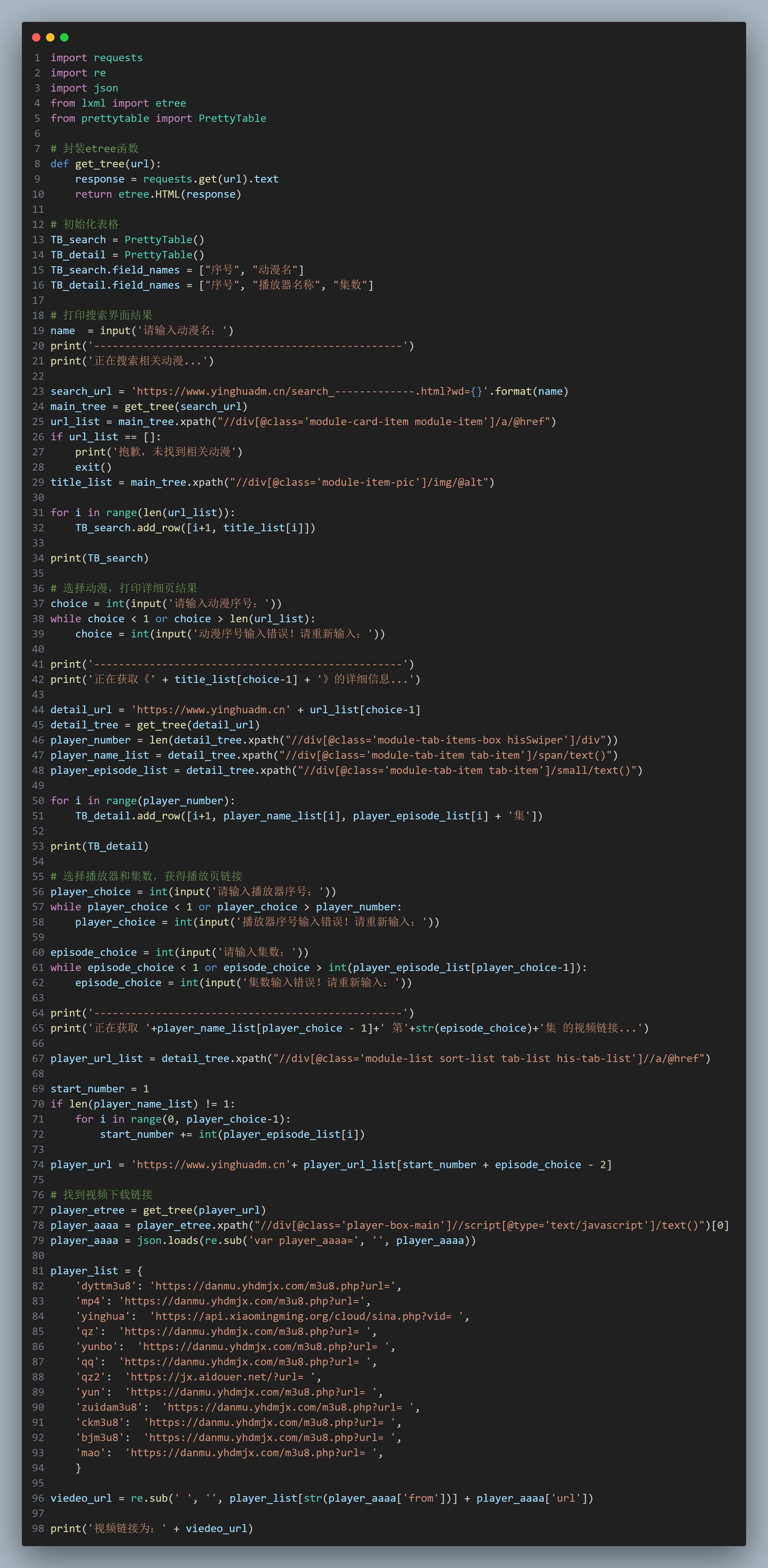
python使用requests+lxml进行网页分析,通过prettytable可视化打造动漫下载器
python使用requests+lxml进行网页分析,通过prettytable可视化打造动漫下载器
效果展示
简单分析搜索页网页元素
分析网页樱花动漫,进行搜索。
例如搜索动漫牧神记,搜索之后跳转的链接为https://www.yinghuadm.cn/search_-------------.html?wd=牧神记,如图所示
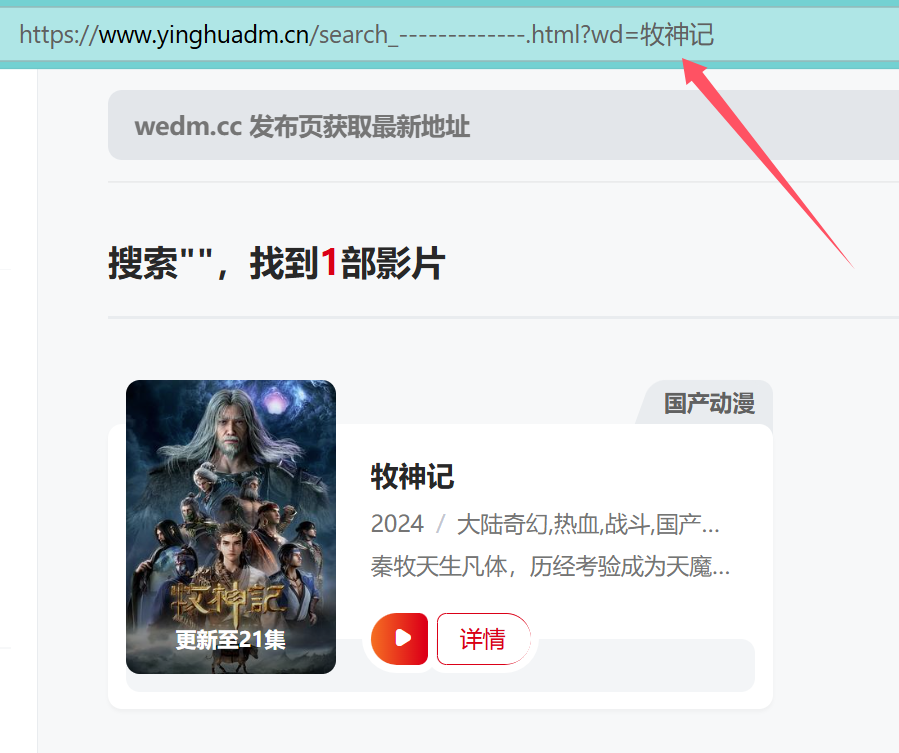
因此可以猜测该网站搜索结果均在上述链接wd=之后,在python中可以先定义变量name,然后访问想要的搜索界面
1 | name = input('请输入动漫名:') |
分析详细页链接如何获得
随后继续点击搜索结果,进入详细界面,发现其链接为https://www.yinghuadm.cn/vod_9004.html,可以发现只需要在https://www.yinghuadm.cn/后面加上vod_及之后的值和.html,便可以访问到该动漫的详细信息。
随后通过检查上一页源码,发现其vod_9004存储在<div class="module-card-item module-item">标签中,如图所示
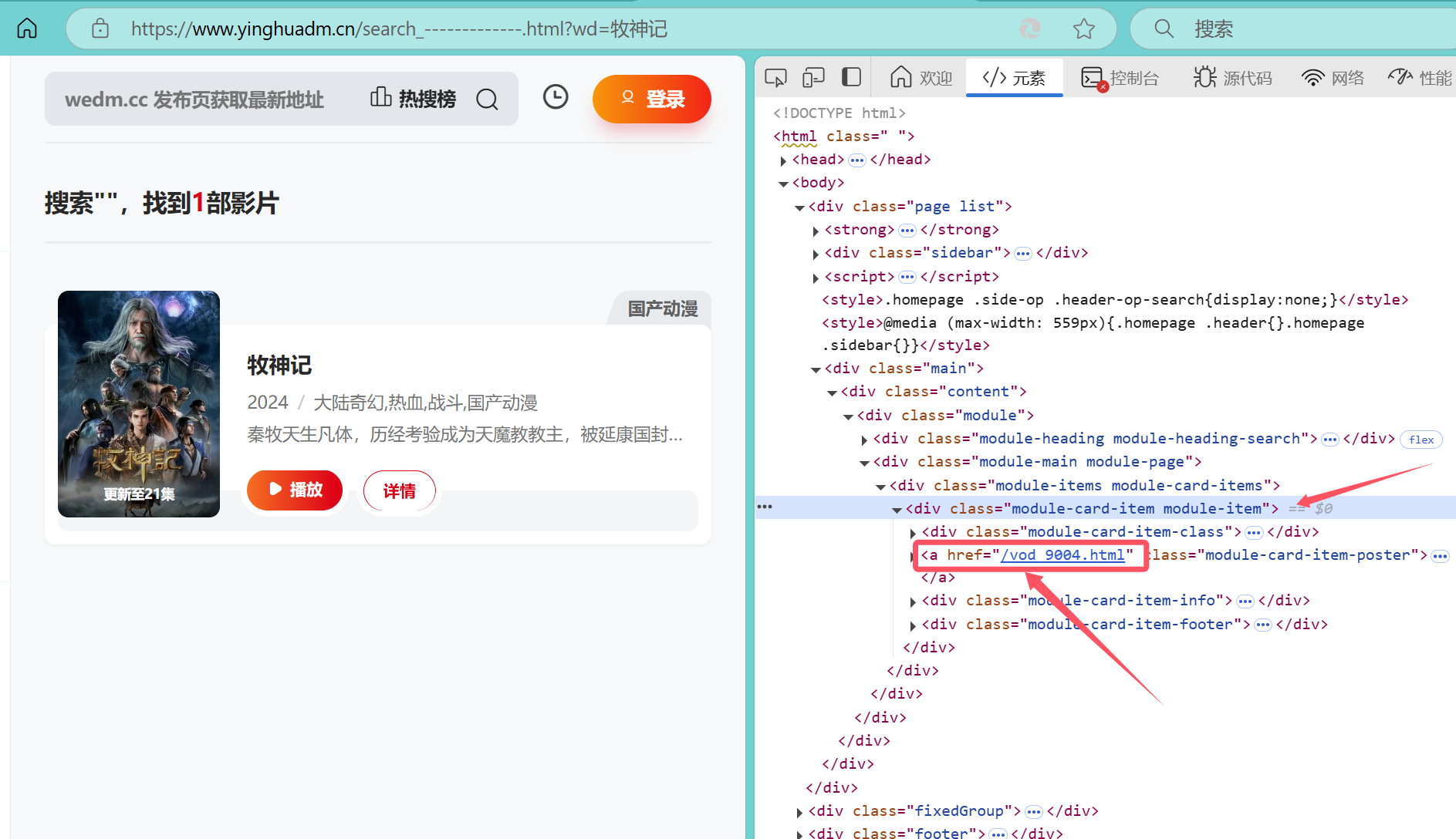
可以通过xpath语法//div[@class='module-card-item module-item']/a/@href来获取该标签里href中的内容(注意这里用etree进行分析之后输出结果为列表的形式,如果搜索结果有多个,可以更容易的逐个进行访问)
分析动漫标题如何获得
继续研究该页源码,发现其标题信息存储在<div class="module-item-pic">标签中,如图所示
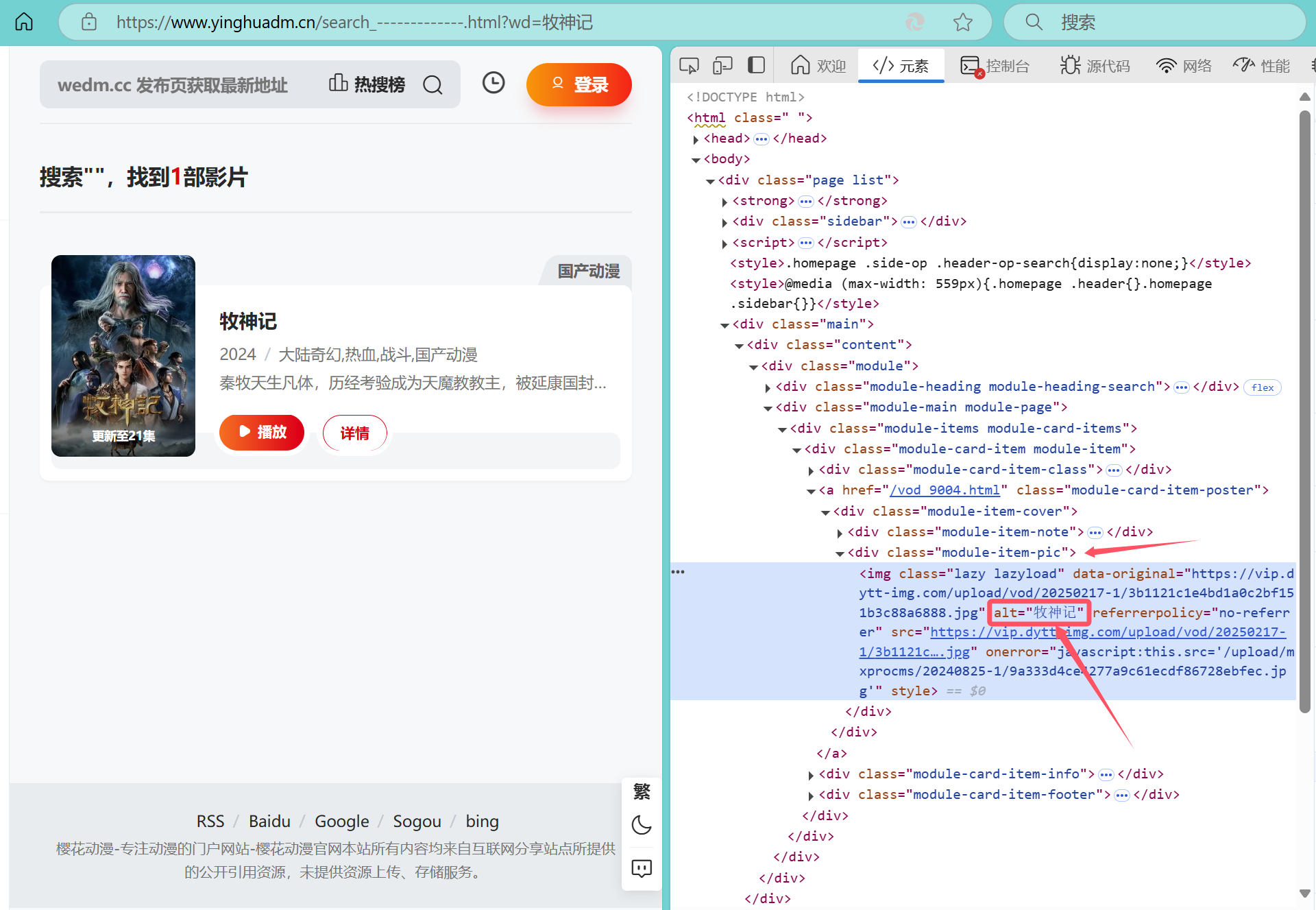
同样可以通过XPath语法//div[@class='module-item-pic']/img/@alt来获取该标签里alt中的内容(同理,这里的输出也为列表形式,可以通过索引实现与vod值对应)
通过代码实现打印搜索结果
这里使用prettytable库,使搜索结果能够更直观的展示出来
1 | TB = PrettyTable() |
首先创建名为TB的表格,随后用requests库获取搜索结果的源码,并用etree库进行分析
1 | search_url = 'https://www.yinghuadm.cn/search_-------------.html?wd={}'.format(name) |
之后用xpath语法获取搜索结果的链接和标题
1 | url_list = main_tree.xpath("//div[@class='module-card-item module-item']/a/@href") |
通过之前的分析,可以了解到两个列表的长度应该相同,可以使用for循环将结果依次加入表格中(注意这里的链接应为https://www.yinghuadm.cn和title_list中的元素拼接而成)
1 | # 定义链接前缀 |
最后打印表格,输出结果如下图

分析详细页信息
可以通过输入序号,来选择要访问的详细页,接着还是以牧神记为例,详情页如图

可以看到所有集的链接均在<div class="module-play-list-content module-play-list-base">标签内的href中
然而通过在源码中查找,发现结果超出范围,原因是有两种不同的播放源造成的
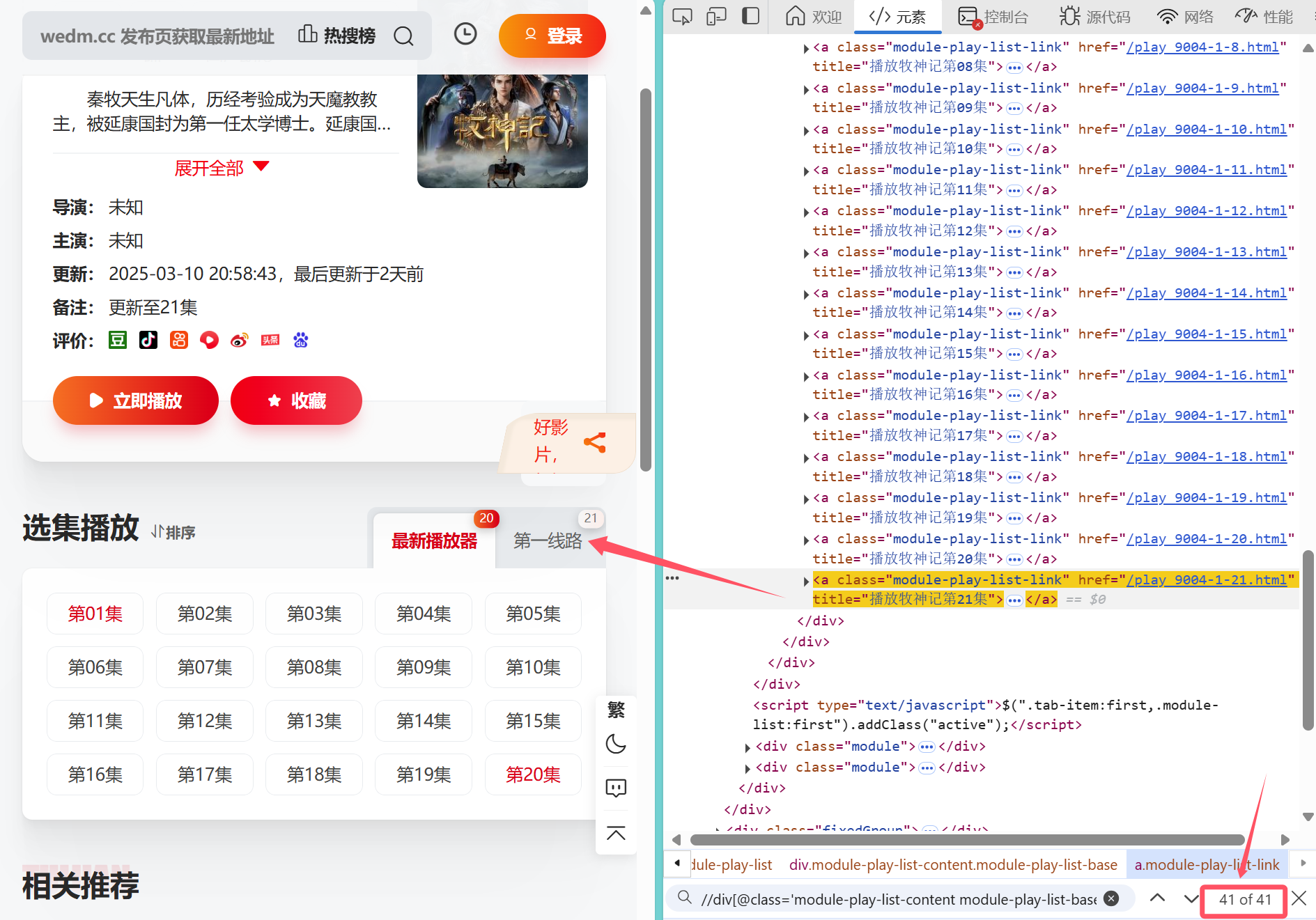
那么再次对页面源码观察,发现不同的播放源所归属的div标签有细微差距,如图所示

接着分析可以发现播放源存放在<div class="module-tab-items-box hisSwiper">标签中,通过对多个页面进行分析,发现默认情况下对应的播放源为<div class="module-tab-item tab-item active">,若还有第二或者第三播放源,均存放在<div class="module-tab-item tab-item">,如图以火影忍者为例

这里的官方路线和备用路线的div标签相同,所以可以通过xpath对上一div标签进行定位,然后获取其中div标签数量,//div[@class='module-tab-items-box hisSwiper']/div,可以用以下代码实现
1 | # detail_tree为详细页源码的etree对象 |
随后可以通过和1比较,如果仅有1个,其xpath为//div[@class='module-tab-item tab-item active'],如果大于1,则均为//div[@class='module-tab-item tab-item'],展开div标签可发现播放器名称在<span>标签中,集数在small标签中,这里不再放图展示
但是通过写代码发现//div[@class='module-tab-item tab-item active']中并无内容,反而都存储在//div[@class='module-tab-item tab-item']中,这也使得代码更加简便
1 | player_name = detail_tree.xpath("//div[@class='module-tab-item tab-item']/span/text()") |
通过这段代码可以将播放器名称和集数分别存入两个列表中,之后再加上前文对//div[@class='module-tab-items-box hisSwiper']/div数量的分析,可以通过循环依次打印,使播放器名称和集数相对应
通过代码实现打印详细页信息
这里要创建第二个表格,用于展示详细页信息,因此将其命名为TB_detail,前边表格更名为TB_search,让代码维护更加方便
1 | TB_detail = PrettyTable() |
然后通过之前的分析,可以把播放器名称和集数分别存入两个列表中,随后通过循环将内容添加到表格中
1 | for i in range(player_number): |
最后打印表格,输出结果如下图,这里以火影忍者为例,因为有3个播放源,能够更好的检测代码是否正确

由于在对每个页面进行分析,获取etree对象时会有重复的步骤,因此可以将其封装成一个函数(同时可以考虑删除TB_search表格中的链接列,展示更加清爽直观,随后可以通过输入序号,来获得链接,从而进行详细页的访问,使其不在输出端显示出来)
获取播放页链接
在前边已经发现播放页链接存放在//div[@class='module-list sort-list tab-list his-tab-list active']//a/@href和//div[@class='module-list sort-list tab-list his-tab-list']//a/@href中,但通过代码调试发现和之前出现的情况相同,//div[@class='module-list sort-list tab-list his-tab-list active']//a/@href中并无内容,代码会变得更加容易,但由于列表内容过多,需要结合不同播放器的集数来分配内容
因此这里需要输入选择的播放器序号,代码如下
1 | player_choice = int(input('请输入播放器序号:')) |
这里的start_number表示当前播放器的起始集数,随后通过输入集数episode_choice,两者相加-1得到该播放器对应的集数,随后通过//div[@class='module-list sort-list tab-list his-tab-list']//a/@href得到所有的播放页链接列表,通过索引拿到对应的播放页链接的后半部分,通过拼接获得完整播放页链接
1 | episode_choice = int(input('请输入集数:')) |
找到视频下载链接
通过对播放页面进行分析,发现视频链接存放在<td id="playleft">中iframe的src中(如图),因此可以直接通过xpath获取该链接,但是很不幸的是,通过在requests获取的网页中,找不到这个标签,原因肯呢个由于网页是动态加载的,需要通过其他途径来获取,在对网页js进行分析时发现,其链接是拼接而成,如图所示
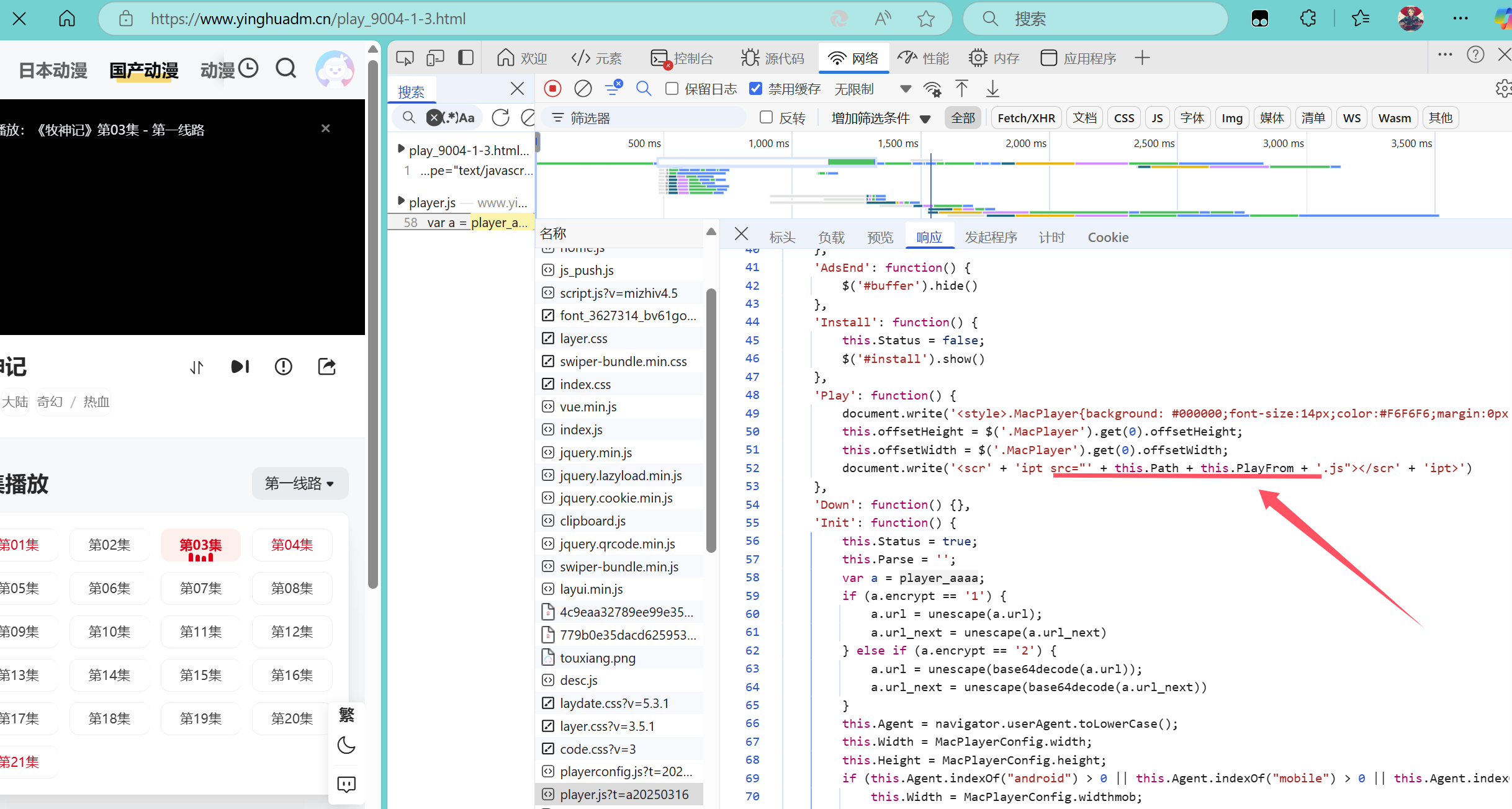
那么只需要找到this.Path和this.PlayFrom这两个变量(this.Path由于对应其他js文件内容过多,因此先分析的this.PlayFrom,但是刚好这个分析完之后可以拿到视频链接,因此这里只展示this.PlayFrom的分析过程),搜索this.PlayFrom,可以在js中找到a.from和MacPlayerConfig.player_list[this.PlayFrom].parse两项,如图所示
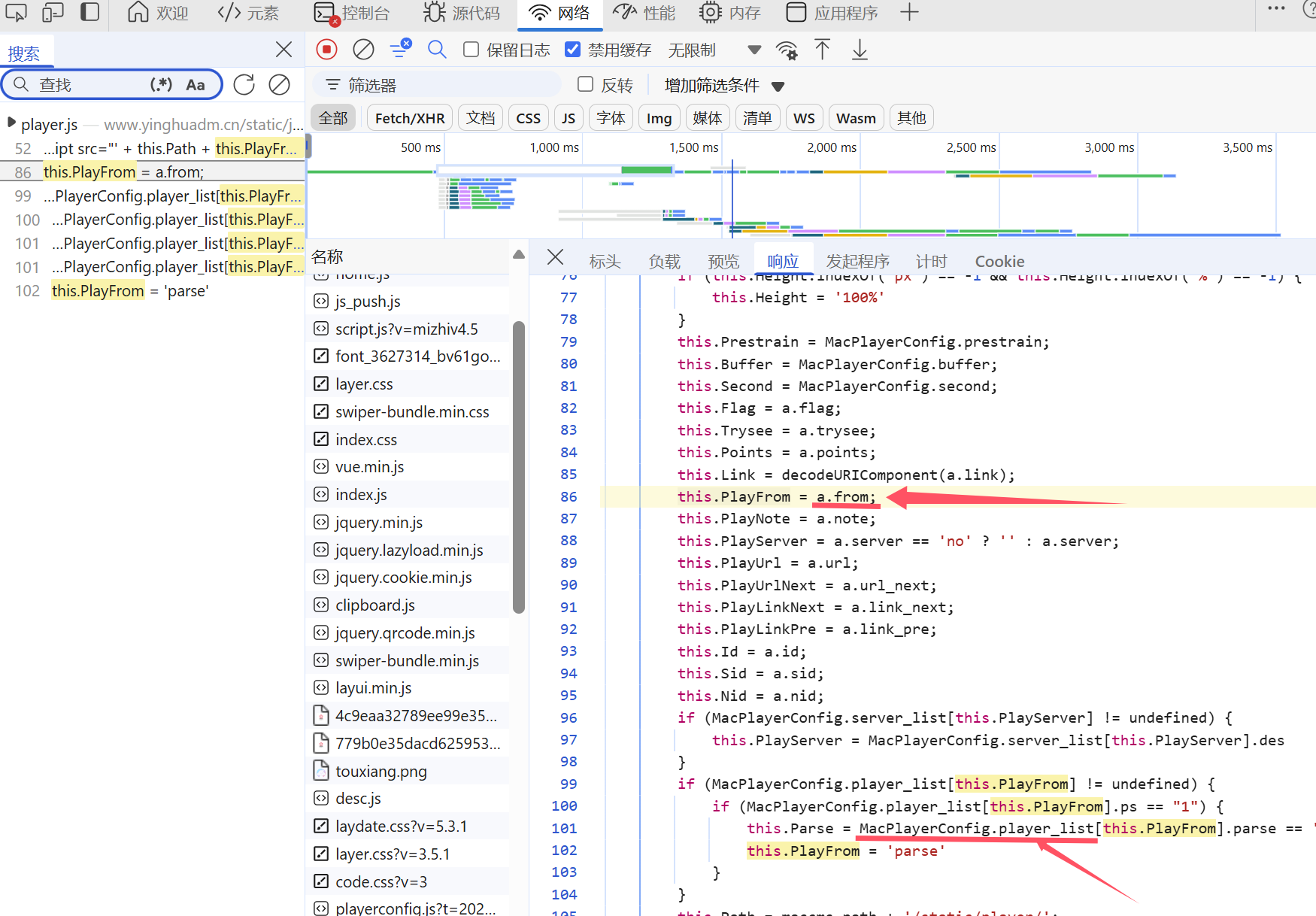
而后者的为字典,其中存储了多个视频类型以及其对应的链接
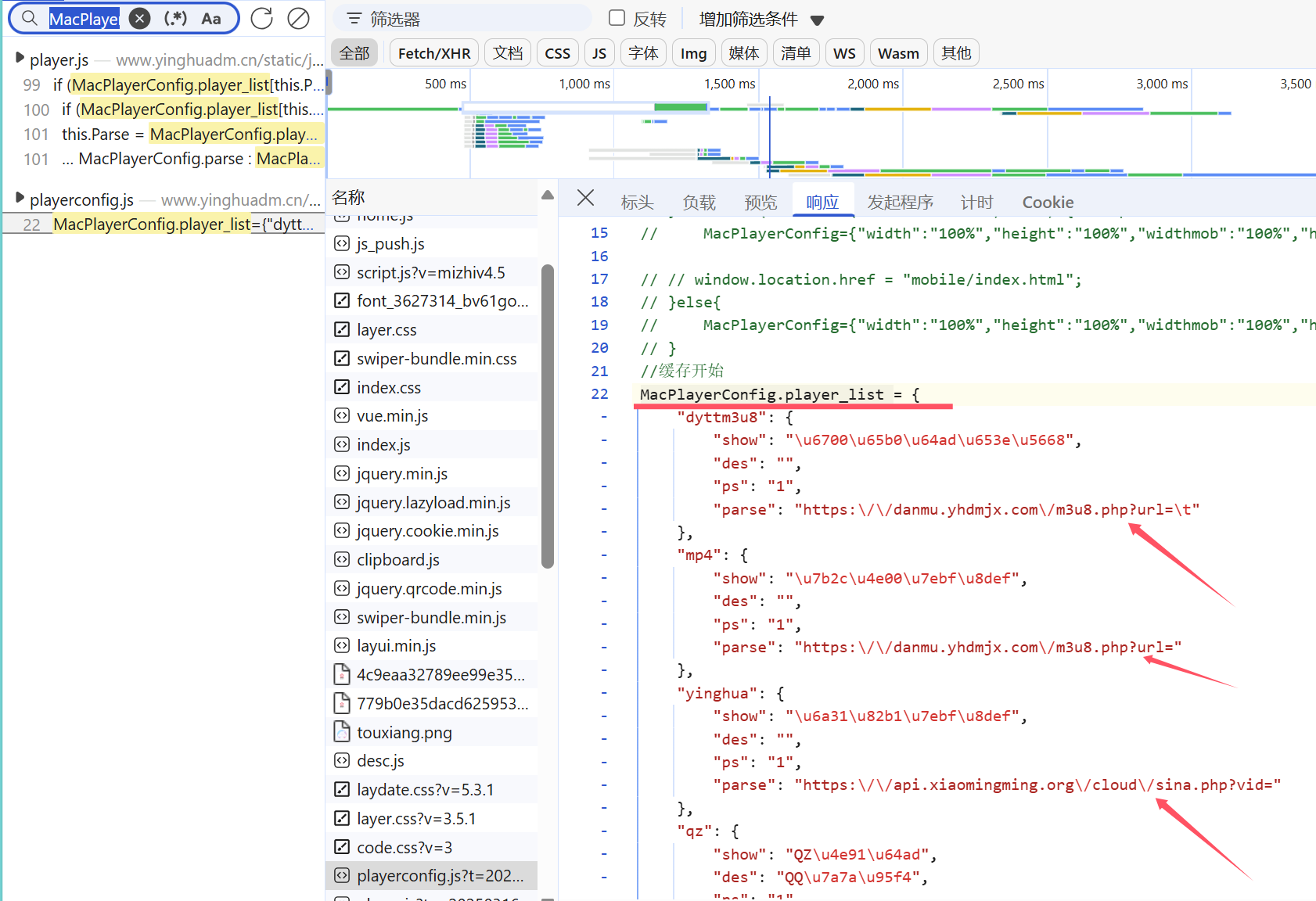
因此,可以猜测链接是通过列表中parse内容及之后的url拼接而成,所以我们可以先在 python文件中创建一个字典来存放不同视频类型对应的链接,同时可以删掉没用的部分,只留下其parse的内容
1 | player_list = { |
接着分析a.from,通过搜索发现只在那个文件中存在,因此向上观看代码,发现其变量a实际上为player_aaaa,如图所示
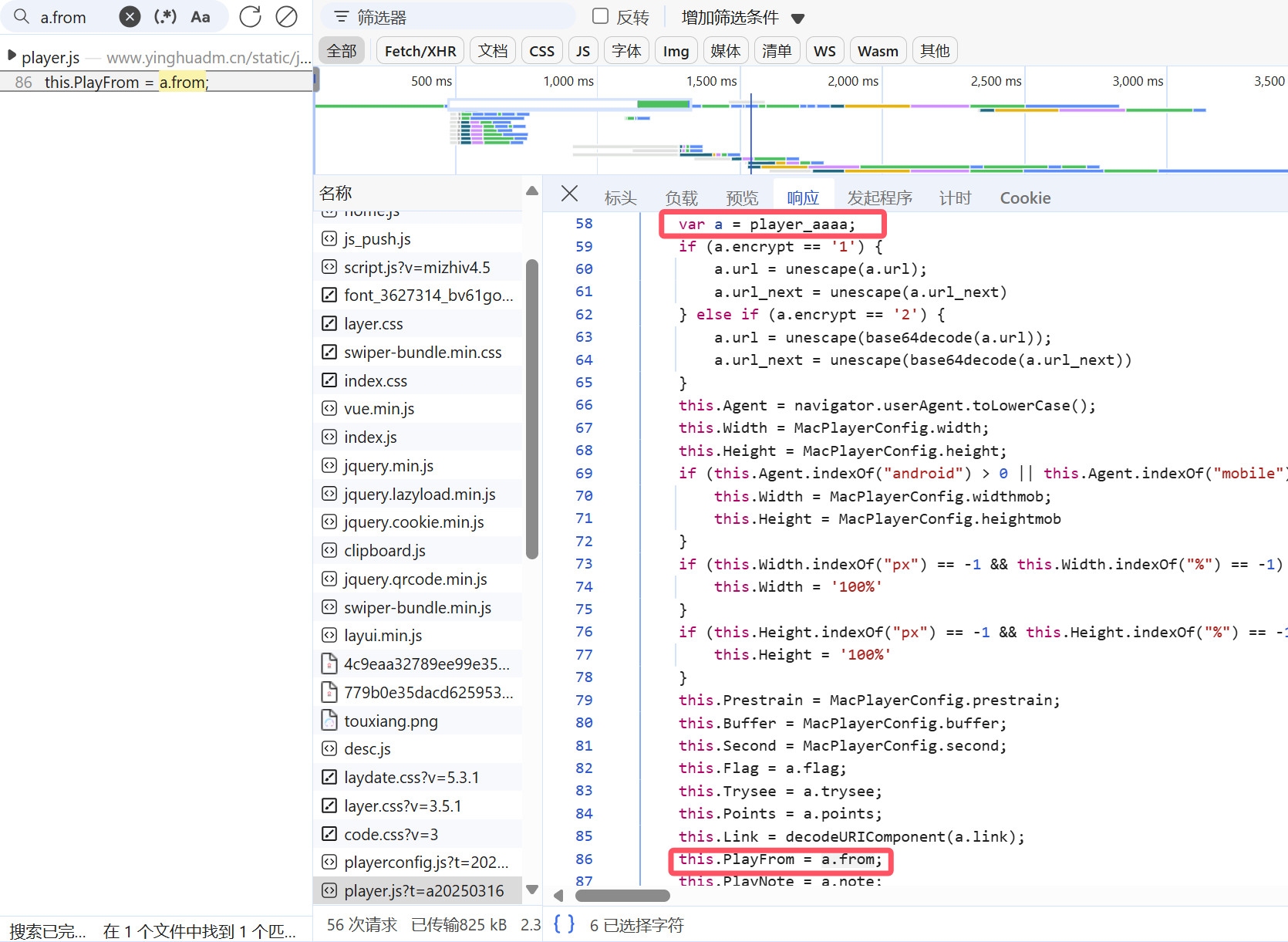
值得庆幸的是,通过搜索发现player_aaaa就在页面源码的<script type="text/javascript">之中,而这个可以通过requests获取,并用xpath分析
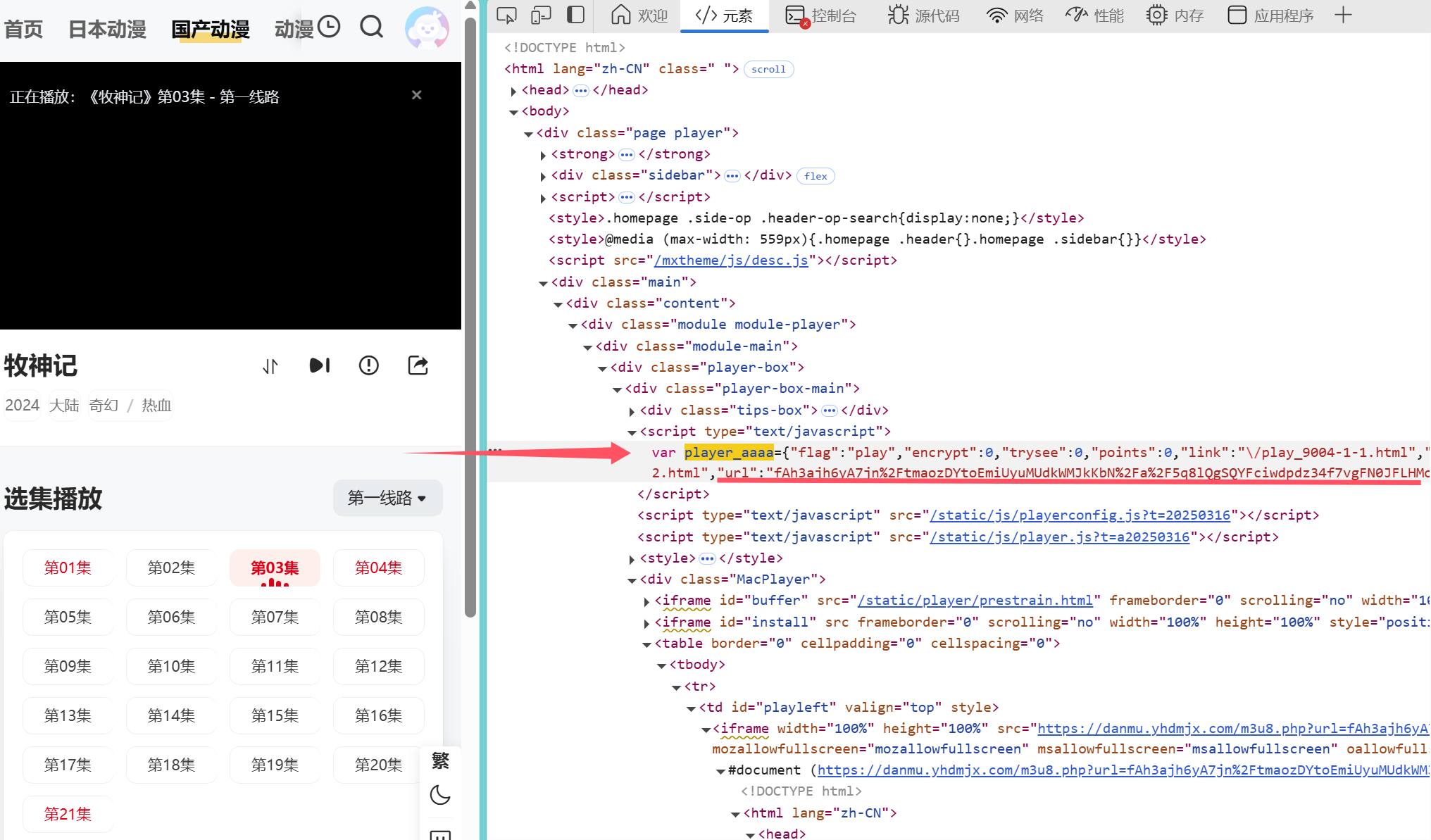
1 | player_aaaa = detail_tree.xpath("//div[@class='player-box-main']//script[@type='text/javascript']/text()")[0] |
通过打印发现其前边多了var player_aaaa=内容,使其不是一个纯的字典类型,我们需要使用re库,用正则表达式将其删除,并通过json库将字符串类型变成字典,随后通过字典来访问其中的url和from,将from中的内容和之前创建的字典匹配,得到链接前缀,随后和url拼接,最终可以获得完整的视频链接

1 | # 正则表达式删除前边多余内容,并转换成字典类型 |
之后拼接出完整的视频链接,代码如下
1 | viedeo_url = player_list[str(player_aaaa['from'])] + player_aaaa['url'] |
(之后的视频页面由于采用动态加载,使用requests库难以实现,故本篇内容到此结束,之后获取下载链接将放到使用playwright库的文章中)
代码的完善
在这里可以考虑一下搜索动漫搜不到任何内容的情况,可以增加一个条件,判断url_list是否为空,如果为空,则输出提示信息,并退出程序
1 | if url_list == []: |
在输入动漫序号,播放器序号以及集数时,也可以判断输入是否合法,并给出提示内容之后重新尝试
1 | choice = int(input('请输入动漫序号:')) |
完整代码